Spring Batch Job
Many applications within the enterprise domain require bulk processing to perform business operations in mission critical environments. These business operations include:
- Automated, complex processing of large volumes information that is most efficiently
- Periodic application of complex business rules
- Integration of information that is received from internal and external systems
**Note:**
Spring Batch is not a scheduling framework. Spring Batch is not a scheduling framework. There are many good enterprise schedulers (such as Quartz, Tivoli, Control-M, etc).
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management.
Usage Scenarios:
A typical batch program generally:
- Reads a large number of records from a database, file or queue.
- Processes the data in some fashion
- Writes back data in a modified form
Business Scenarios:
- Commit batch process periodically
- Concurrency batch processing: parallel processing of a job
- Staged, enterprise message-driven processing
- Massively parallel batch processing
- Manual or Scheduled restart after failure
- Sequential processing of dependent steps (with extensions to workflow-driven batches)
- Partial processing: skip records (for example, on rollback)
- Whole-batch transactions, for cases with a small batch size or existing stored procedures/scripts
**Technical Objectives:**
- Batch developers use the Spring programming model: Concentrate on business logic and let the framework take care of infrastructure
- Clear separation of concern between he infrastructure, the batch execution
- Provide common, core execution services as interfaces that all projects can implement
- Provide simple and default implementation of the core execution interfaces that can be used “out of the box”
- Easy to configure, customize, and extend services, by leveraging the spring framework in all layers
- All existing core services should be easy to replace or extend without any impact to the infrastructure layer
- Provide a simple deployment model, with the architecture JARs completely separate from the application, built using Maven
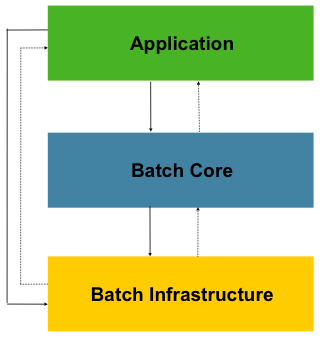
Spring BATCH Architecture
Spring batch is designed with extensibility and a diverse group of. end users in mind. The figure. below shows the. layered architecture that. supports the extensibility and ease of use for end-user developers.
General Batch Principles and Guidelines
- Remember that a batch architecture typically affects on-line architecture and vice versa. Design with both architectures and environments in mind using common building blocks when possible.
- Simplify as much as possible and avoid building complex logical structures in single batch applications.
- Keep the processing and storage of data physically close together (in other words, keep your data where your processing occurs).
- Minimize system resource use, especially I/O. Perform as many operations as possible in internal memory.
- Review application I/O (analyze SQL statements) to ensure that unnecessary physical I/O is avoided. In particular, the following four common flaws need to be looked for:
- Reading data for every transaction when the data could be read once and cached or kept in the working storage.
- Rereading data for a transaction where the data was read earlier in the same transaction.
- Causing unnecessary table or index scans.
- Not specifying key values in the WHERE clause of an SQL statement.
- Do not do things twice in a batch run. For instance, if you need data summarization for reporting purposes, you should (if possible) increment stored totals when data is being initially processed, so your reporting application does not have to reprocess the same data.
- Allocate enough memory at the beginning of a batch application to avoid time-consuming reallocation during the process.
- Always assume the worst with regard to data integrity. Insert adequate checks and record validation to maintain data integrity.
- Implement checksums for internal validation where possible. For example, flat files should have a trailer record telling the total of records in the file and an aggregate of the key fields.
- Plan and execute stress tests as early as possible in a production-like environment with realistic data volumes.
- In large batch systems, backups can be challenging, especially if the system is running concurrent with on-line on a 24-7 basis. Database backups are typically well taken care of in the on-line design, but file backups should be considered to be just as important. If the system depends on flat files, file backup procedures should not only be in place and documented but be regularly tested as well.
